Since the dawn of deep neural network-related technologies, the combination of vision and language modalities has become one of the mainstream research areas in both computer vision and natural language processing communities. We have been working on the following topics in this area.
Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation
Have you ever looked at a painting and wondered what is the story behind it? This work presents a framework to bring art closer to people by generating comprehensive descriptions of fine-art paintings. Generating informative descriptions for artworks, however, is extremely challenging, as it requires to 1) describe multiple aspects of the image such as its style, content, or composition, and 2) provide background and contextual knowledge about the artist, their influences, or the historical period. To address these challenges, we introduce a multi-topic and knowledgeable art description framework, which modules the generated sentences according to three artistic topics and, additionally, enhances each description with external knowledge. The framework is validated through an exhaustive analysis, both quantitative and qualitative, as well as a comparative human evaluation, demonstrating outstanding results in terms of both topic diversity and information veracity.
You can find more details including the paper and code here.
Uncovering Hidden Challenges in Query-based Video Moment Retrieval
The query-based moment retrieval is a problem of localising a specific clip from an untrimmed video according a query sentence. This is a challenging task that requires interpretation of both the natural language query and the video content. Like in many other areas in computer vision and machine learning, the progress in query-based moment retrieval is heavily driven by the benchmark datasets and, therefore, their quality has significant impact on the field. In this paper, we present a series of experiments assessing how well the benchmark results reflect the true progress in solving the moment retrieval task. Our results indicate substantial biases in the popular datasets and unexpected behaviour of the state-of-the-art models. Moreover, we present new sanity check experiments and approaches for visualising the results. Finally, we suggest possible directions to improve the temporal sentence grounding in the future.
You can find more detail with the code and results here.
A dataset and baselines for visual question answering on art
Answering questions related to art pieces (paintings) is a difficult task, as it implies the understanding of not only the visual information that is shown in the picture, but also the contextual knowledge that is acquired through the study of the history of art. In this work, we introduce our first attempt towards building a new dataset, coined AQUA (Art QUestion Answering). The question-answer (QA) pairs are automatically generated using state-of-the-art question generation methods based on paintings and comments provided in an existing art understanding dataset. The QA pairs are cleansed by crowdsourcing workers with respect to their grammatical correctness, answerability, and answers’ correctness. Our dataset inherently consists of visual (painting-based) and knowledge (comment-based) questions. We also present a two-branch model as baseline, where the visual and knowledge questions are handled independently. We extensively compare our baseline model against the state-of-the-art models for question answering, and we provide a comprehensive study about the challenges and potential future directions for visual question answering on art.
The dataset and code will be available soon.
Visual question answering with knowledge
Visual question answering is a popular research topic recently, and many papers have been published. As its name suggests, this task explores a system that can answer a question on a given input image, which means that the answer should appear in the image.

In this work, we propose a novel video understanding task by fusing knowledge-based and video question answering. First, we introduce KnowIT VQA, a video dataset with 24,282 human-generated question-answer pairs about a popular sitcom. The dataset combines visual, textual, and temporal coherence reasoning with knowledge-based questions, which need the experience obtained from the viewing of the series to be answered. Second, we propose a video understanding model by combining the visual and textual video content with specific knowledge about the show. Our main findings are: (i) the incorporation of knowledge produces outstanding improvements for VQA in videos, and (ii) the performance on KnowIT VQA still lags well behind human accuracy, indicating its usefulness for studying current video modeling limitations.
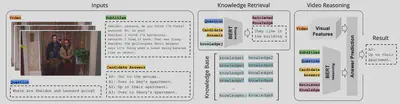
Our dataset is available here.
Unsupervised scene descriptions for Knowledge Video-QA
Tounderstandmovies, humans constantly reason over the dialogues and actions shown in specific scenes and relate them to the overall storyline already seen. Inspired by this behaviour, we design ROLL, a model for knowledge-based video story question answering that leverages three crucial aspects of movie understanding: dialog comprehension, scene reasoning, and storyline recalling. In ROLL, each of these tasks is in charge of extracting rich and diverse information by 1) processing scene dialogues, 2) generating unsupervised video scene descriptions, and 3) obtaining external knowledge in a weakly supervised fashion. To answer a given question correctly, the information generated by each inspired-cognitive task is encoded via Transformers and fused through a modality weighting mechanism, which balances the information from the different sources. Exhaustive evaluation demonstrates the effectiveness of our approach, which yields a new state-of-the-art on two challenging video question answering datasets: KnowIT VQA and TVQA+.
These results are published at ECCV.
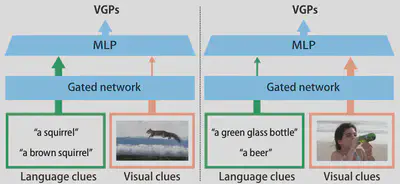
Visually grounded paraphrases
Visually grounded paraphrases (VGPs) describe the same visual concept but in different wording. Previous studies have developed models to identify VGPs from language and visual features. In these existing methods, language and visual features are simply fused. However, our detailed analysis indicates that VGPs with different lexical similarities require different weights on language and visual features to maximize identification performance. This motivates us to propose a gated neural network model to adaptively control the weights. In addition, because VGP identification is closely related to phrase localization, we also propose a way to explicitly incorporate phrase-object correspondences. From our evaluation in detail, we confirmed our model outperforms the state-of-the-art model.
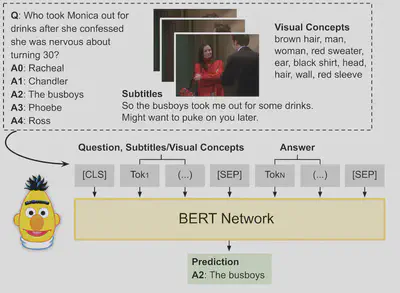
Transformer-based models for visual question answering
Visual question answering (VQA) aims at answering questions about the visual content of an image or a video. Currently, most work on VQA is focused on image-based question answering, and less attention has been paid into answering questions about videos. However, VQA in video presents some unique challenges that are worth studying: it not only requires to model a sequence of visual features over time but often it also needs to reason about associated subtitles. In this work, we propose to use BERT, a sequential modeling technique based on Transformers, to encode the complex semantics from video clips. Our proposed model jointly captures the visual and language information of a video scene by encoding not only the subtitles but also a sequence of visual concepts with a pre-trained language-based Transformer. In our experiments, we exhaustively study the performance of our model by taking different input arrangements, showing outstanding improvements when compared against previous work on two well-known video VQA datasets: TVQA and Pororo.
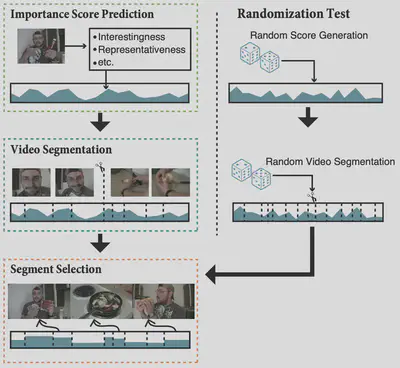
Video summarization
Video summarization is a technique to create a short skim of the original video while preserving the main stories/content. There exists a substantial interest in automatizing this process due to the rapid growth of the available material. The recent progress has been facilitated by public benchmark datasets, which enable easy and fair comparison of methods. Currently, the established evaluation protocol is to compare the generated summary with respect to a set of reference summaries provided by the dataset. In this paper, we will provide an in-depth assessment of this pipeline using two popular benchmark datasets. Surprisingly, we observe that randomly generated summaries achieve comparable or better performance to the state-of-the-art. In some cases, the random summaries outperform even the human-generated summaries in leave-one-out experiments. Moreover, it turns out that the video segmentation, which is often considered as a fixed pre-processing method, has the most significant impact on the performance measure. Based on our observations, we propose alternative approaches for assessing the importance scores as well as an intuitive visualization of correlation between the estimated scoring and human annotations.