Conventional cameras mimic human vision system and capture an image that can be understood by humans. However, it is not always necessarily to take human understandable image in computer vision tasks. Computational photography rethink the whole pipeline of computer vision system including hardware such as optics, sensors and software processing in order to solve the target task. We are developing new cameras and processing to obtain high-quality images and videos, reconstruct an object shape and understand a scene.
Inverse Scattering
We propose an inverse rendering model that estimates 3D shape, spatially-varying reflectance, homogeneous subsurface scattering parameters, and an environment illumination jointly from only a pair of captured images of a translucent object. In order to solve the ambiguity problem of inverse rendering, we use a physically-based renderer and a neural renderer for scene reconstruction and material editing. Because two renderers are differentiable, we can compute a reconstruction loss to assist parameter estimation. To enhance the supervision of the proposed neural renderer, we also propose an augmented loss. In addition, we use a flash and no-flash image pair as the input. To supervise the training, we constructed a large-scale synthetic dataset of translucent objects, which consists of 117K scenes. Qualitative and quantitative results on both synthetic and real-world datasets demonstrated the effectiveness of the proposed model. For more detail, please check our project website.

Compressive Video Sensing
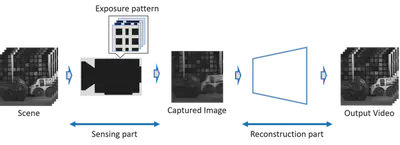
There is a trade-off between spatial and temporal resolution of the camera, for examples. the spatial resolution of high-speed camera is often lower than that of still camera, and the frame rate of still camera is lower than that of video camera. This trade-off comes from sensor readout limit, and it is not drastically improved by sensor technology. Compressive sensing is the different approach to solve this problem. It sparsely samples the video by using random exposures of the sensor and reconstruct the full resolution and frames of the video as post-processing. We have demonstrated to reconstruct the x16 higher fps video (240fps) from the 15 fps sensor. We studied to optimize the exposure pattern of sparse sampling for the better reconstruction under the feasible exposure controls of the sensor. We also proposed deep sensing framework that simultaneously optimizes the best exposure pattern and reconstruction model by using end-to-end leaning of deep neural network.
Action Recognition from a Single Coded Image
There is an increasing demand to analyze human actions from these cameras to detect unusual behavior or within a man-machine interface for Internet of Things (IoT) devices. The action recognition uses a video for analyzing a motion of a scene. Compressive video sensing uses a coded exposure image which containing different time of the scene information. We tackled the problem that It is possible to recognize an action in a scene from the single coded image. We proposed reconstruction-free action recognition from the single coded exposure image. We used deep sensing framework which models camera sensing and classification models into convolutional neural network (CNN) and jointly optimize the coded exposure pattern and classification model simultaneously. We demonstrated that the proposed method can recognize human actions from only the single image. We also compared it with competitive inputs, such as low-resolution video with a high frame rate and high-resolution video with a single frame in simulation and real experiments.
The detail is in the youtube presentation video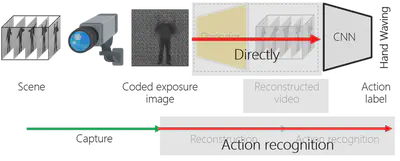
Compressive Light Field Sensing
Light field is used for computer graphics and vision applications, such as free-view display, digital re-focusing, 3D reconstruction and object recognition etc. The image has multiple 2D images with different viewpoints simultaneously. Light field usually captured by camera array or micro-lens array camera. It is difficult to capture a high resolution of light field and not usually affordable to take a video, since the sensor the amount of the data is so huge from the high dimensional nature of light field. We proposed a compressive light field sensing which effectively acquire and reconstruct the light field. We used programmable aperture camera to capture a few coded images with different aperture patterns, then reconstruct full light field with dense view point. We also realized the 5D light field video acquisition and reconstruction. For more detail, please see the project page.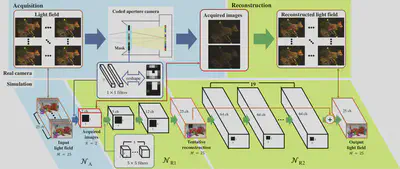
Light Field Segmentation
We proposed a supervised four-dimensional (4D) light field segmentation method that uses a graph-cut algorithm. Since 4D light field data has implicit depth information and contains redundancy, it differs from simple 4D hyper-volume. In order to preserve redundancy, we define two neighboring ray types (spatial and angular) in light field data. To obtain higher segmentation accuracy, we also design a learning-based likelihood, called objectness, which utilizes appearance and disparity cues. We show the effectiveness of our method via numerical evaluation and some light field editing applications using both synthetic and real-world light fields.
For more detail, please see the project page.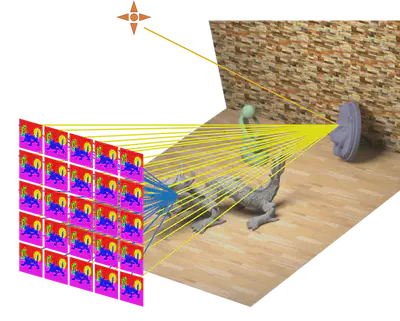
Object Shape and Reflectance reconstruction from Light Field
Reflectance and shape are two important components in visually perceiving the real world. Inferring the reflectance and shape of an object through cameras is a fundamental research topic in the field of computer vision. While three-dimensional
shape recovery is pervasive with varieties of approaches and practical applications, reflectance recovery has only emerged recently. Reflectance recovery is a challenging task that is usually conducted in controlled environments, such as a laboratory
environment with a special apparatus. However, it is desirable that the reflectance be recovered in the field with a handy camera so that reflectance can be jointly recovered with the shape. To that end, we present a solution that simultaneously recovers the
reflectance and shape (i.e., dense depth and normal maps) of an object under natural illumination with commercially available handy cameras. We employ a light field camera to capture one light field image of the object, and a 360-degree camera to
capture the illumination. The proposed method provides positive results in both simulation and real-world experiments.
Transparent Object Recognition using Light Field
Recognizing the object category and detecting a certain object in the image are two important object recognition tasks, but previous appearance-based methods cannot deal with the transparent objects since the appearance of a transparent object dramatically changes when the background varies. Our proposed methods overcome previous problems using the novel features extracted from a light-field image. We propose a light field distortion (LFD) feature, which is background-invariant, for transparent object recognition. Light field linearity (LF-linearity) is proposed to measure the likelihood of a point comes from the transparent object or not. The occlusion detector is designed to locate the occlusion boundary in the light field image.
Transparent object categorization is performed by incorporating the LFD feature into the bag-of-features approach for recognizing the category of transparent object. Transparent object segmentation is realized by solving the pixel labeling problem. An energy function is defined and Graph-cut algorithm is applied for optimizing the pixel labeling problem. The regional term and boundary term are from the LF-linearity and occlusion detector output. Light field datasets (available by request) are acquired for the transparent object categorization and segmentation. The results demonstrate that the proposed methods successfully categorize and segment transparent objects from a light field image.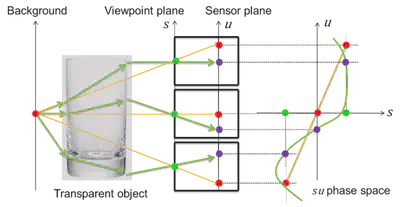
Shape from Shading and Polarization
There are a lot of cues for letting us the 3D object shape from an image. We introduced a method to recover the shape from shading and polarization. This is motivated by the
fact that photometric stereo and polarization-based methods have complementary abilities. The polarization-based method can give strong cues for the surface orientation and
refractive index, which are independent of the light source direction. However, it has ambiguities between two possible choices of the surface orientation. In contrast, photometric stereo method can disambiguate the surface orientation
and give a strong relationship between the surface normals and light source directions. However, it has limited performance for large zenith angles, refractive index estimation. Taking their advantages, our proposed method can recover the shape for both small and large zenith angles, the light source directions, and the refractive indices of the object. The proposed method is successfully evaluated by simulation and real-world experiments.
Coded Aperture Camera
It is widely known that the camera aperture adjusts the amount of light and controls the point spread function (PSF) of the camera imaging system. Coded aperture imaging engineers the PSF by special aperture shapes. It has attracted a lot of attention in recent years. Traditional coded aperture imaging is achieved by inserting a cutout cardboard or printed photo-mask into the lens and, therefore, does not allow the pattern to be changed easily. While various aperture patterns have been proposed in the applications for image deblurring, depth estimation based on defocused scene images (depth from defocus), and light-field imaging, the optimal aperture depends on the shooting conditions, such as lighting and scene context. Some applications also require a combination of two or more patterns. In this study, we developed a programmable aperture camera that uses a liquid crystal on silicon (LCoS) to actively set the aperture pattern. This programmable aperture camera is able to adaptively capture an image with apertures suitable for individual scenes and shooting conditions. Also, the camera can capture a light-field image at high speed. To consider imaging by utilizing the programmability of the camera, we are searching for newer coded imaging techniques and applications.
Focus-sweep Camera
We developed a focus-sweep camera capable of engineering the point spread function (PSF) of the camera by controlling the focus of the lens. We propose focus-sweep imaging, which produces a superimposed image with different size blurring by moving the imaging device or lens along the optical axis during exposure. Unlike coded aperture imaging, focus-sweep imaging can control the PSF with an open-up aperture and, therefore, has the advantage that it can produce images with a higher SN ratio. By using different combinations of sweeping trajectories and exposure timings of imaging devises, we successfully implemented a variety of imaging techniques and applications, including extended depth of field, depth from defocuses, tilted depth of field, discontinuous depth of field, and curved depth of field. The traditional coded imaging technique requires a special lens and aperture. On the other hand, focus-sweep imaging, which controls the point spread function by changing the lens focus, can use the auto-focus mechanism, which consumer cameras already have. For this reason, we believe that focus-sweep imaging is practical and feasible. This study was conducted in collaboration with Columbia University. For more information, see this page.